Start Trek
Apprendre à une IA à poser un module lunaire. Un agent de reinforcement learning entraîné sur LunarLander, doublé d'un site éditorial pour documenter et visualiser chaque run.

Faire atterrir un agent, et rendre son apprentissage lisible.
Start Trek explore le reinforcement learning sur l'environnement LunarLander en comparant deux approches - DQN en discret, TD3 en continu. Au-delà de l'entraînement, j'ai construit un site vitrine éditorial pour documenter les hyperparamètres, comparer les runs et visualiser les courbes de récompense.
- +Implémentation des agents DQN et TD3
- +Conception de la boucle d'entraînement et du replay buffer
- +Tuning des hyperparamètres et analyse des runs
- +Site vitrine Next.js pour documenter les résultats
- +Visualisation des courbes de récompense
Deux algorithmes, un terrain
DQN apprend une politique discrète, TD3 une politique continue. Les faire tourner sur le même environnement met en lumière leurs forces : stabilité contre finesse de contrôle.
Rendre l'entraînement lisible
Un run de RL, c'est des milliers d'épisodes et beaucoup de bruit. J'ai logué et tracé la récompense, l'epsilon et la perte pour comprendre quand et pourquoi, l'agent apprend à atterrir.
Un site comme carnet de bord
Plutôt qu'un notebook brut, une vitrine éditoriale : chaque expérience a sa page, ses paramètres, ses courbes. Le code rencontre le design pour raconter la recherche.
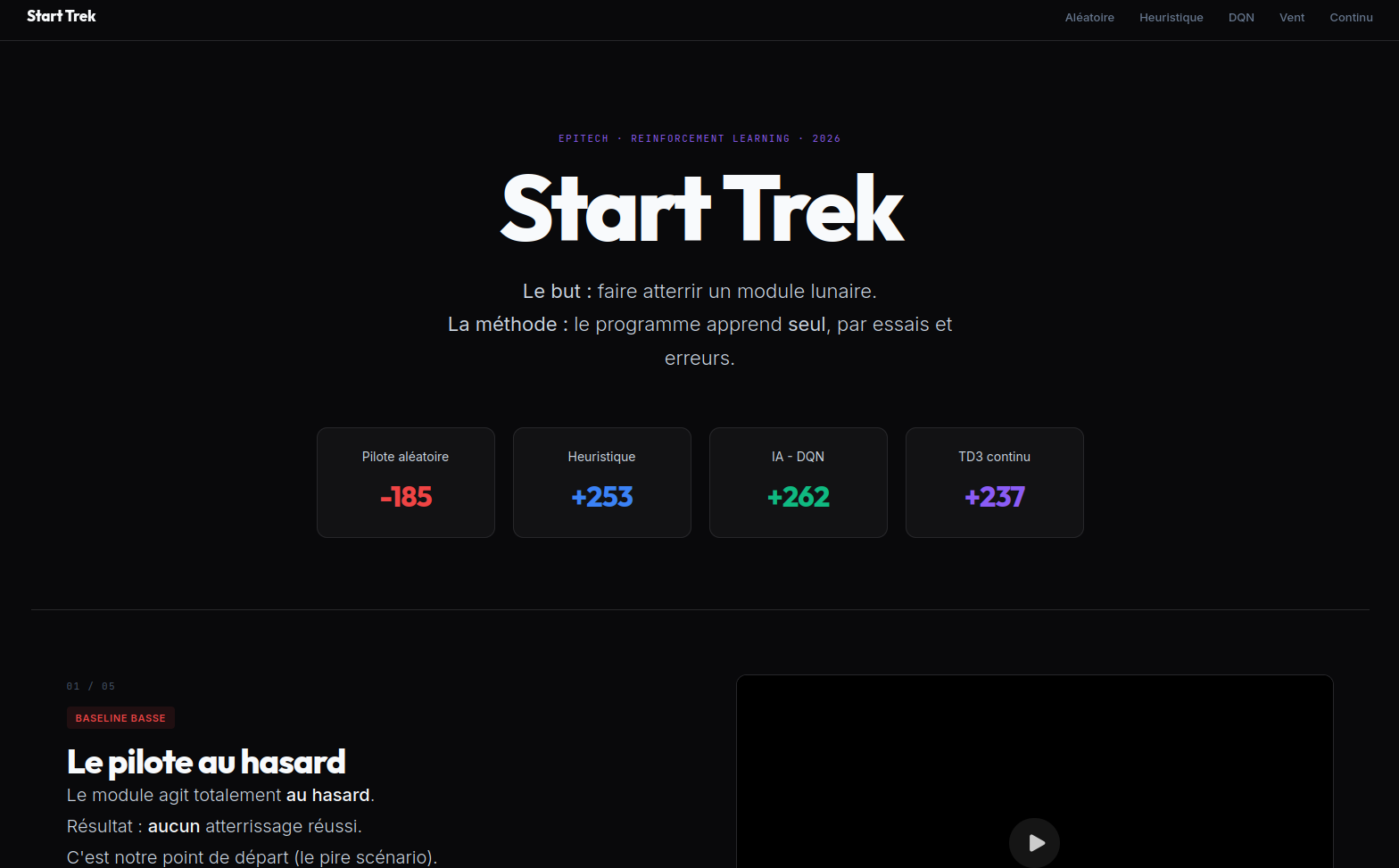
Un agent qui se pose proprement, et surtout une manière claire de montrer comment il a appris à le faire.